The Nonstop Organization: Embracing the Era of Intelligent, Continuous Flux
The multi-year, big-bang transformation program is over. What replaces it is continuous flux: change as a permanent operating state, not an event.
 Read on the web →
Read on the web →Data Privacy Compliance for AI Systems
A practical checklist for keeping AI systems on the right side of privacy and compliance obligations.
Download the resource →Federated Learning
Training shared AI models on data that never leaves each owner's firewall: collective intelligence without surrendering proprietary data.
Read the explainer →A cartoon, a teaser, and a little levity.
Julia Child's Fearless Experimentation
At the outset, let me confess I am not a connoisseur of French food, and, while I cook, I am not a great cook either.
However, through the occasional cooking shows I watch and the profiles in the media, I find Julia Child to be an inspiration.
Julia Child didn’t speak French when she moved to Paris, and apparently, she’d barely cooked before attending Le Cordon Bleu. But it seems she approached every kitchen disaster with curiosity rather than defeat. Once, when she dropped a turkey on live TV, she simply picked it up and continued cooking, showing millions that perfection isn’t the goal, learning is.
Leadership Takeaway for Me (and some of you as well):
- Public Resilience: How you handle mistakes in front of your team matters more than avoiding them.
- Curiosity Over Perfection: The best leaders are the best learners, not the most polished performers.
- Authenticity Builds Trust: People follow leaders who show their humanity, not their flawlessness.
True leadership isn’t about never failing; it’s about failing forward with grace and humor. What do you think? Are there other such figures from whom you draw your inspiration and leadership lessons? I appreciate you sharing your thoughts in the comments.
The Scaling Paradox
A startup’s AI system performance follows this pattern:
- 1-100 users: 99% uptime
- 101-1000 users: 95% uptime
- 1001-10000 users: 90% uptime
- 10001+ users: 85% uptime
If downtime costs $100 per user per hour, and they gain 100 users per week, starting with 50 users, when does the weekly downtime cost first exceed $10,000?
Answer at the foot of the issue ↓
The Scaling Paradox
The weekly downtime cost first exceeds $10,000 after 1 week (when they reach 150 users and drop to 95% uptime).
The Math:
Let the weekly hours be (24×7). If uptime is , then expected downtime hours per week is:
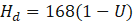
Downtime cost is $100 per user per downtime hour, so weekly downtime cost at N users is:
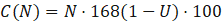
Week 0 (start): 50 users, 99% uptime
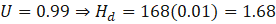 hours
hours
C(50)=50 \cdot 1.68 \cdot 100 = 50 \cdot 168 = $8,400]
So it’s below $10,000 at the start.
After 1 week: 150 users (gain 100), now in the 101–1000 tier at 95% uptime
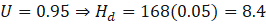 hours
hours
C(150)=150 \cdot 8.4 \cdot 100 = 150 \cdot 840 = $126,000]
That’s above $10,000.